1 Lancement du hackathon
- organisation diverses (contrats, autorisation, horaires, où manger à 12h, etc.)
- programme des deux journées
- rappel des attendus du hackathons: pas d'attendu productif / travail ensemble : il faut que ça apporte aussi aux participants (comprendre comment foncitonne le code de Paged.js)



2Tour de table: présentation des participants
- Tour de table de pésentation: la plupart des paricipants se connaissent mais c'est une bonne manière de lancer le hackathon (Louis: « J'aime bien que ça soit un peu formel aussi (les présentations), comme ça, ça fait un bon début de workshop »)
- Présentations générales et «dirigées» (en lien avec les technos du web)



3Partage de livres
Partage de livre fait avec Paged.js (ramenés par Julie), les livres passent de mains en mains


















Retours d'expérience de projets avec Paged.js et discussions
- Tour de table avec des exemples de réalisations utilisant Paged.js ou des outils proches
- Mise en exergue de problématiques rencontrées dans l'utilisation
- Discussions en rebond entre les participants
4Julie: discussion Villa Chiragan
- Discussion engagée suite au livre feuilleté par Louis
- Julien ouvre un salon sur le mattermost pour ces deux jours, espace pour se partager des trucs (permet d'échanger des liens et fichiers plus rapidement)








5Robin
Thèse: « Le vacillement des formats : matérialité, écriture et enquête : le design des publications en Sciences Humaines et Sociales »
Thèse publiée à la fois en format web et en format print / multiformat fait avec Ovide mais écrit avec GoogleDocs
Ovide = outil créé dans le cadre de sa thèse et qui permet de faire du multisupport











6Sarah
- Livre Controverses. Mode d'emploi (workflow, outil, choix graphiques, scripts utilisés, choses qui ont génée dans paged.js)
- Début de discussion sur les stratégies qui peuvent être déployées pour éviter les gènes


























7Manu
- Editoria, booksprint












8Louis
- do.doc + sparrow

















9Julie (Chiragan)
- utilisation de Paged.js dans la villa Chiragan (grille)










10Expérimentations Paged.js (Julie)
- présentation du repo "experiment" de paged.js et notamment les scripts qui sont à travailler et qu'on pourrait continuer à travailler
- sidenotes, margin notes
- images pleines page
- NE1A4963.MOV / 00:13:43 présentation de là où nous en sommes pour les footnotes, script en cours de Fred + travail de specification autour des notes
- NE1A4964.MOV / Discussion autour des notes + comment on s'organise pour travailler dans paged.js et proposer des specifications (quelles sont nos réflexions)


















11Julien
















12Julien / code source Paged.js









Julie: discussion villa Chiragan
Sarah: (à propos de Chiragan) Ça fait pas longtemps que vous l'avez reçu non ?
Julie: Oui, en fait le musée a fait des corrections, et puis l'imprimeur ça a été long... Ça a durée, ça a durée...
Louis: Et alors là, par exemple, le master HTML, l'imprimeur modifie des trucs directement dedans ?
Julie: Je leur envoie le PDF en RVB... Plusieurs mois en avance je lui avais envoyé un fichiers d'exemple. L'imprimeur, il a un Adobe Acrobat plus poussé que nous. Par exemple, je lui donne la webcolor, et je lui dis que je veux que ce soit en Pantone et lui il transforme tout. Les iamges pareil, en fait, elles sont pas réellement coupées dans le PDF donc tu peux les remplacer. Et quand tu les recadres, elles sont plus grande en réalité.
Louis: Oui, oui, pour les fond perdus ?
Julie: Les fonds perdus c'est prévu dans Paged.js mais dans ton fichier même – tu vois là, par exemple, cette image – beh en réalité elle est grande comme ça. Il y a toute l'image qui est sauvegardée dans le PDF. Et lui, il fait la conversion, il a un truc automatique en fait.
Louis: Mais je veux dire dans le process avec Paged.js, est-ce que vous avez bénéficié de la séparation forme/contenu qui permet du coup de facilement changer le contenu ? La méthodologie du projet en gros, avec le client.
Julie: C'était avec Antoine Fauchié, et on leur avait fait... C'est le musée qui est spécialement
venu nous voir pour ça parce qu'ils avaient vu ce que faisait The Getty Museum à Los Angeles. Ils
avaient vu la présentation d'Antoine à ce propos, et il voulait un truc comme ça. C'était un peu
pour eux un truc novateur, pour bien montrer ce qu'ils font au musée. Et du coup, on a fait le site
web. Je sais pas si tu l'as vu aussi. Mais on a fait un site web, aussi. Je pourrais te le montrer. On
a mis en place un site avec Jeckyll et on leur a fait ... Attends je te montre le site. Ils voulaient
absolument écrire une seule fois le contenu. [montre à l'écran] Donc, ça c'est le site. En fait,
il est très complet le site, il y a beaucoup de sculptures et chacune ont leur notice. Donc par exemple,
pour el livre, on ne pouvait pas tout mettre donc on a choisit trois notices par chapitres bien
développées mais sinon ça renvoyait au site. Et la chaîne de publication, elle est ici [montre billet de
blog]. On a mis en place Jeckyll, en mettant Zotero dessus parce qu'il y avait beaucoup de références
biblio. Eux, ils voyaient Forestry.io en fait. C'est un truc où tu peux brancher des sites hugo,
jeckyll... qui leur permet d'avoir une interface qui est plus... Voilà, eux, c'est un peu comme ça
leur interface, tu vois. ils sont plus habiutés ça. Et du coup, avec Jeckyll, on faisait le site web mais
il y avait une page spéciale impression.html, qui avait un gabarit différent pour mettre que
les notices dont on avait besoin. Mais ça mettait à jour à chaque fois qu'ils modifiaient, c'était
branché à Git en fait. À chaque fois que tu enregistres sur Forestry, ça pushait sur git en fait. Donc,
c'est ça qu'on avait mis en place.
Julien: Tes fichiers qui vont à l'impression, ils ont une métadata qui informe Jeckyll, ou tu recréé ... ?
Julie: Au bout d'un moment, franchement, j'ai séparé. Parce que j'ai voulu faire les drapeaux en fait. Et j'ai séparé trop tôt. Parce que bien sûr, quand tu leurs dit que c'est fini, c'est pas fini.
Sarah: Ouai...
Julie: Et là bien sûr, c'était carrément pas du tout fini. La moitié des textes ont été réécrits.
Julien: Tu es content d'avoir fait la moitié des drapeaux.
Julie: Mais du coup, je le referais autrement. Les drapeaux, je le laisserais dans forestry, je m'en fiche qu'ils le voient. Si au bout d'un moment je leur dis que c'est fini, c'est leur faute s'il y a des caractères bizarres en plus pour l'impression.
Julien: Les drapeaux, tu les as fait avec des <br>?
Julie: Oui, entourés d'une class printpour l'enlever quand je suis en web. Enfin...
C'est ce que j'aurais fait mais vu que j'ai séparé finalement, j'ai pas eu le temps.
Robin: Et comment tu as fait ça, avec quel outil ? Dans le navigateur, directement dans l'inspecteur, ou avec le code à côté ?
Julie: Franchement, c'était plutôt pas mal réglé les drapeaux... enfin, au final c'est moche avec le recul. J'ai fait beaucoup aussi d'espaces insécables pour les mots à deux lettres. Donc, j'ai automatisé. Après, certains trucs je les ai refait à la main donc ça a pris un peu de temps. Mais maintenant, franchement, je saurais mieux l'optimiser. En fait, l'avoir fait une fois, ça m'a guérie. Je le ferais autrement en fait. [...]
Julie: Tiens, j'ai partagé le lien de Chiragan. En tous cas, l'article que j'ai partagé, il y a tout le process si tu veux voir.
Julie: Mais, avec l'imprimeur ça s'est super bien passé honnêtement. En plus, vu que le photographe faisait la photogravure, ils ont remplacé les photos même après que j'ai fini le PDF.
Julien: Donc, tu as quand même un travail.
Julie: Il suffisait que les photos soient 3 fois plus grandes.
Julien: Et ton PDF, il fait quelle taille.
Sarah: Ah, la question.
Julie: On va regarder, je sais même pas si je l'ai pas enlevé de mon ordi.
Julien: 3,5 gigas ?
Sarah: Ha oui, tant que ça ?
Julien: Beh c'est possible avec les images en haute déf.
Julie: Les images elles sont en bonne qualité et il y en a beaucoup quand même.
Julien: Et puis haute qualité, ça veut dire qu'en plus, ça m'étonne que tu as pas dû les resizée.
Julie: Si, je les ai resizée un peu. Mais quand même...
Julie: 200 mégas.
Julien: Ouai, ça va.
Sarah: Oui, tu vois, c'est pas... Moi j'avais 365.
Julie: Ha non, pardon, c'était pas le bon. 900 mégas.
Julien: Oui c'est ça, ça me paraît plus logique.
Julie: Attends parce qu'il y avait des fichiers beaucoup plus petits. Ha oui, parce qu'il y avait des tests aussi... On l'a pas fait mais il y avait des bichromies. Et finalement, ils ont gardé la couleur.
Sarah: Sur les photos ?
Julie: Sur les photos à la fin, l'espèce de liste. Et on a fait les tests. Il y a eu un test imprimeur avant pour être sûr. Ils avaient pas le bon papier, c'est pour ça que ça a repris 3 mois derrière. Donc, voilà.
Robin
Transcrit depuis [DR0000_0089.mp3, 00:34:23]
Robin: Alors moi, rapidement, le plus gros truc que j'ai fait avec Paged.js, c'est ça, c'est ma thèse. Donc, qui est une thèse que j'ai publiée à la fois en format web et en format print, pour le rendu. D'ailleurs j'ai ramené... J'ai trouvé que des épreuves, donc c'est vraiment très moche au niveau matériel. Mais si vous voulez regarder à quoi ça ressemblait quand même au niveau du format. Ça, c'est le premier quart de la thèse.
Robin: Donc là ce que j'affiche [à l'écran], c'est la version HTML du print, mais bien sûr, il y avait aussi un PDF. Je dois l'avoir mis quelque part dans mes trucs. Ça sera peut être mieux. Et j'ouvre peut-être la version web. Voilà donc, une des versions web ressemblait à ça. Je vais pas passer du temps sur la version web. Mais il y avait plusieurs version web; dont celle-ci qui était la plus traditionnelle disons, avec un texte et des notes sur le côté, et puis des choses qui se passent sur la droite. Et le PDF, qui nous intéresse ici, ressemblait à ça. Donc, c'est une thèse avec un texte qui est justifié comme vous le verrez dans le corps si je passe à un endroit, ici. Mais qui est aussi assez travaillé du point de vue des différentes formes d'hypertextualité qu'il y a à l'intérieur. C'est-à-dire qu'il y a notamment un système de références bibliographiques... Alors, je vais essayer d'en trouver une à un endroit. Voilà, ici. Un système de références bibliographiques qui fonctionne dans les deux sens; c'est-à-dire que sur le PDF, on peut cliquer sur une référence et l'avoir en entier; et depuis les références, on peut voir – comme pour les index en fait – où chacune des références bibliographiques est utilisée et resauter dessus. Il était censé y avoir la même chose avec l'index mais finalement, il y a pas eu. Je pourrais vous expliquer pourquoi... En fait, je voulais le faire et puis, j'ai pas réussi.
Julie: Tu as pas réussi à cause de Paged.js ou à cause d'autre chose ?
Robin: Non, c'est ... Alors, attends, il faut que je me rappelle pourquoi... C'est parce que j'avais trop d'éléments d'index en fait. Et donc, pour repérer chacun des éléments d'index et revenir en arrière... Enfin, par rapport à la manière dont je gérais les index, j'arrivais à un temps de calcul pour computer tout mon index qui était vraiment énorme, qui est en entier sur le site. Qui marchait pas, notamment parce que j'étais à 10 jours du rendu; de la fermeture de la fac pour rendre la thèse, et du coup, j'ai laissé tombé. Voilà. Attends, j'essaie juste de montrer des figures d'un des chapitres au moins. Il y avait un système de figures, voilà. Donc ça, je l'ai fait officiellement ... enfin, initialement, je voulais le fabriquer avec un outil que j'ai développé dans le cadre de ma thèse, qui s'appelle Ovide. Ovide, c'est un outil – très rapidement – qui permet de faire de la publication multisupport.
[...]
Le reste de la transcription n'est pas disponible en version publique.
Sarah
Transcrit depuis [NE1A4957.MOV / 00:04:20]
Sarah: Pour continuer par rapport à ce que disais Robin, moi, le plus gros projet que j'ai fait avec Paged.js, c'est ce livre-là [Controverses] – qui était aussi le premier finalement. Avant c'était des tests, c'est le premier vrai livre – qui était toute une aventure. Le workflow qu'on avait imaginé à la base, c'était d'utiliser une version détournée de Fonio qui s'est appelée Goji en attendant. L'idée c'était de partir de Fonio, de travailler avec Robin et de demander à Robin des améliorations, notamment l'intégration de Paged.js. Pour que Clémence Seurat, qui était la directrice éditoriale, et aussi, d'autres personnes du médialab qui bossaient sur les bouquins, puissent entrer les contenus directement en ayant une interface assez simple et qui est vraiemnt faire pout ça. Ça c'était, un peu le sommaire de ce qui s'était passé. Du coup, on avait ajouté des systèmes de tags pour taguer les pages pour que les différentes pages aient des classes que je puisse sélectionner parce qu'il y avait tout un système de couleur. Donc, on a fait ça pendant un moment et puis en fait, quand vraiment, le vrai contenu est arrivé et il a fallu rentrer des images qui étaient assez lourdes, etc., on s'est rendu compte que ça allait être compliqué. Le truc des images ça prenait longtemps, l'éditeur ramait beaucoup, il y avait des histoires du curseur qui était pas positionné au bon endroit
ROBIN: Ça n'avait jamais était testé sur une si grosse publication.
Sarah: Moi, ça allait. Du coup, le process, c'était qu'il y avait ça. Après, dans « édition », on peut exporter une édition. Ce que j'ai pas mal fait moi, c'est que j'ai pas mal exporté des bouts du bouquin pour pouvoir le tester au début, puis pour pouvoir faire un export complet. À partir du moment où on a décidé d'arrêter, même si c'était pas ça l'idée de base, j'ai fait un export complet de ce qu'on avait fait et ensuite, on a intégrer tous les contenus directement en HTML, à la main. Mais, il y avait déjà beaucoup de contenus qui avaient étaient entrés dans Goji.
Louis: Parce que ça devenait trop difficile d'utiliser l'éditeur, c'est ça ?
Sarah: Oui, en fait, l'éditeur, il y avait trop de contenu et du coups ça ramait trop et, je sais pas... j'ai mis une semaine à rentrer une partie des contenus, c'était trop long, c'était pas possible. Je crois qu'Inès et Clémence, elles ont passé trois jours complets à faire que ça, rentrer les contenus. En attendant, ça ramait de ce que j'ai compris. Moi, j'étais pas là à ce moment-là. Donc, à un moment, on a dit, on arrête. Il y avait pas beaucoup de contenus à ajouter donc on s'est dit, c'est pas grave, on arrête, on change et on est passé à une version HTML pure.
Louis: Ça c'était en local sur ta machine ?
Sarah: En local sur ma machine.
Louis: Tout se faisait sur ta machine ?
Sarah: Oui.
Louis: Avec elle au-dessus de ton épaule qui te disait quoi faire ?
Sarah: Elle m'envoyait en fait les trucs à rentrer et puis moi je les machinais.
Julie: C'était relu et corrigé avant de t'envoyer ?
Sarah: Euh... non. Il y avait quand même... Tout avait été relu mais les corrections, elles se sont faites directement sur le PDF après. Donc en fait, l'idée d'avoir une séparation du contenu et de la forme et que moi je touche pas le contenu et les corrections; ça n'a pas fonctionné beaucoup parce que je leur ai pas laissé la main sur le HTML.
Louis: Tu aurais voulu ou c'était trop court au niveau du temps ?
Sarah: Le timing était trop short, c'était trop stressant, il y avait trop de trucs à faire et du coup... En fait, il faut savoir que les textes finis, on les a eu début octobre et il fallait imprimer début novembre. Pour un bouquin de 320 pages, c'était un peu compliqué. Finalement, on a imprimé fin novembre. Mais bon, les timing étaient vraiment vraiment short.
[...]
Le reste de la transcription n'est pas disponible en version publique.
Louis / do.doc
Louis: L'idée c'est de créer des documents page à page dans lesquels on pourrait déposer des choses enregistrées à côté. Mais évidemment, l'idée c'était pas de copier [l'élément dans la page] mais de garder un lien dynamique. Si quelqu'un est en train d'écrire dans le texte collaboratif, je veux voir mon texte s'éditer ici [sur la page]. (...) Avec le temps, on s'est aperçu que c'était contraignant de devoir mettre les éléments dans la base de donnée avant de les mettre dans le document, donc maintenant tu peux directement cliquer sur "capturer", prendre une photo et sans qu'elle provienne directement d'un projet, tu peux direct tout mettre dans un document.
[...]
Louis: L'idée c'est que dans certain cas tu veux pas être dans un projet, tu veux juste créer un document page à page; tu as pas besoin de l'associer à un projet. C'est des choses que les enseignants nous ont montré, ils veulent juste avoir un espace où ils se mettent en plein écran comme ça et ils font leur mise en page directement en plaçant directement les éléments. Il y a aussi un truc de dessin libre qu eue suis en train de travailler, pour annoter, faire des choses comme ça.
[...]
Le reste de la transcription n'est pas disponible en version publique.
Julie: Je voulais vous remontrer Chiragan. En fait, j'ai beaucoup travaillé la grille, la baseline. Déjà il y a la baseline, mais aussi, je me suis amusée à ce que la grille tombe parfaitement sur des multiples. Donc c'est une grille CSS
Louis: Une grille CSS avec des background ?
Julie: Non, une CSS grid. Pour chaque page, j'ai mis une div image; il y a un saut de page avant/après, mais c'est surtout que j'utilise display: grid` et vous voyez la hauteur, c'est vraiment des variables et des calculs où je mets la hauteur de mes rows qui est 5 fois la baseline, multiplié par le nombre de rows plus les gap. En fait j'ai tout fait avec des variables et bien m'en a pris parce que j'ai changé la taille de ma page en plein milieu du travail, de 5mm et vu que c'est des variables tout est resté calé. Je voulais aussi que le code soit lisible et visible. C'était un truc tout simple. Après, chaque image à un id, chaque grille a un id et après à partir de l'inspecteur, je regarder pour positionner sur ma grille en fonction. Les figcaption sont tournées et alignées sur la grille. Elles sont moins avec un id et plus par rapport à la page sur laquelle elles se trouvent: page de gauche, de droite; elles sont souvent au même endroit, du coup j'ai pas mis d'id particulier. L'idée c'était de garder un rythme dans les cahier d'image, je me suis amusée à changer le positionnement des images sur la grille. Des fois, pour le rythme, il y a aussi des images en pleine page.
Julie: La deuxième chose que j'ai faite, c'est que pour les notices, souvent il y a 3 pages de textes et moi je voulais que les images soient en plein milieu du texte. Le problème que si je mets une image en pleine page, il y a souvent du blanc dans le texte avant. Louis, tu vois ce que je veux dire ?
[...]
Le reste de la transcription n'est pas disponible en version publique.
Julie: Ensuite, je voulais vous montrer, on a ce petit repo dont s'est servi Sarah.
Sarah: Ha oui, je m'en suis servi pour pleins de trucs.
Julie: Il y a ce petit repo "experiment" [sur le gitlab] où il y a pleins de trucs qu'on est en train d'expérimenter et quo'n a plus ou moins fini. Par exemple, table of content il est souvent repris parce que c'est un script qui permet de recréer automatiquement une table des matières. "Baseline" c'est un script que j'avais fait il y a un moment.
Sarah: j'ai pas réussi à le faire fonctionner correctement.
Julie: Oui, ça m'étonne pas. Il essayait de caler les choses automatiquement sur une ligne de base mais en fait pour des designers, c'est un peu chiant, c'est super restrictif.
Sarah: Après, c'est ce que fait InDesign finalement.
Julie: Oui c'est ce que fait Indesign, mais là il le faisait automatiquement pour tous les éléments, c'est pour ça que c'était chiant. Après, pour les margins notes, dont Sarah a parlé. C'est quelque chose dont on pourra discuter aujourd'hui. Par exemple, s'il y a trop de notes dans une colonne, comment faire pour passer à l page suivante ? Parce que le script marche bien, les notes se calent bien. On voit bien par exemple que la cinquième note a été un peu décalée parce que sinon elle tombait sur la 4. (...)
Julie: Et ce que je voulais vous montrer... Alors, je l'ai mis hier, parce que j'ai essayé de me replonger dans les scripts et ça va pas du tout. C'est un script qui a jamais été fini...
Julien: Lequel ?
Julie: Les images. En fait, il y a 2 scripts. Il y a le fait de mettre les images en haut d'une page, on sait faire, Julien va vous montrer après; et même bouger vers le bas ou sur les côtés. Mais il y a d'autres choses: l'image pleine page que je vous ai montré tout à l'heure avec la sculpture. Là, le mieux c'est quand même de rajouter une page. Et du coup, c'est un script que Julien avait commencé à faire. (...) Sans le script, l'image est entre ces deux paragraphes, mais vu qu'elle rentre pas, elle passe à la page suivante. Ce que permet le script, c'est de dire: si je rencontre l'image, tu l'enlèves mais tu continue de rendre le texte et puis quand tu as fini la page, tu créais une nouvelle page et tu poses l'image dessus. Tu poses un nouvel élément, et puis tu continues. Et en fait, pourquoi il y a deux scripts... C'est parce que je me souviens plus trop ce qu'on a fait et je me souviens plus quel est le dernier donc il faudra vérifier; Mais celui-là par exemple, il en ajoute deux pages parce que c'est quand on veut faire une image en spread. Ce dossier là par exemple, il y a pas le script, c'est juste du CSS, donc il faut re-fussioner les trucs. Donc voilà, s'il y en a qui veulent travailler sur ça on peut. Là comment j'ai fait pour le mettre en spread: en réalité, il y a deux images dans une images, c'est du CSS et j'ai même mis des variables pour que tout se modifie d'un coup quand on la bouge ou on la zoome. (...)
[...]
Le reste de la transcription n'est pas disponible en version publique.
Hybrid
Julien: Je vais vous montrer Hybrid. Je vais vous montrer tous mes books parce qu'il y a pleins de choses dedans. (...) L'idée c'était, je vous pouvoir depuis mon site internet avoir un bouton Paged.js et pouvoir avoir une prévisualisation de ce que ça donnerait à l'imprimé et on voudrait pouvoir avoir des options d'accessibilité. Donc c'est vraiment le niveau basique puisque c'est le proto,plus que proto. On a paged.js qui est rendu ici comme un iframe, dans mon fichier j'ai un ensemble de configurations qui me permettent de décider de ce que je veux avoir dans ma preview et quel contenus je veux garder. (...) Donc on a la possibilité de changer les marges; à chaque mise à jour de mes contenus et de mes inputs, il me recharge la page. Donc ça marche sur des petits contenus, faire ça sur un bouquin ça n'aurait aucun sens. Et ici ce qui est fondamental, c'est le passage à une autre typo, en particulier quand on commence à imaginer si on peut avoir plusieurs formats de typo pour les dyslexiques et ce genre de choses. (...)
[...]
Le reste de la transcription n'est pas disponible en version publique.
Julien: Je vous fait la total de comment j'ai bossé, comme ça vous avez une bonne idée. J'ai un ensemble de scripts et de hooks qui vont tourner dans Editoria et qui vont prendre le DOM, le modifier. Ça va se passer à plusieurs moment: d'abord il va y avoir avant que le contenu soit lu; après que le contenu et le CSS soient étudiés; avant que la page soit mise en page; après que la page soient mise en page. Il y a un truc qui permet de tester s'il y a un overflow; c'est ça le truc qui va nous sauver un peu la vie.
[Julien commente le code] Donc le premier truc que je fais, c'est de rajouter un peu des petites maisons (icones) en svg puisque dans Editoria ça n'existe pas. Et après, j'ai besoin de re-créé tout mon DOM. Je récupère un HTML, je sais comment il est construit, je sais comment je le veux à la sortie. Derrière, je fais un ensemble de scripts. le premier, je rajoute des span dans (?); je récupère les h4 et j'en fais des titres h3 qui vont dans le paragraphe suivant (....).
Robin: Qu'est-ce que ça représente "content" dans ton code [hooks] ?
Julien: J'y viens. Chaque hook a un ensemble de méthode et un ensemble de propriétés sur lesquels il va avoir un impact. BeforeParsed, 'content', c'est le contenu qui est récupéré depuis ton HTML, qui est mis dans un élément template HTML, qui n'existe pas en vrai dans le DOM. Donc tous les changements que tu vas faire ici, tu vas les faire dans un template et une fois que tu as fini tout ça, il va faire la mise en page. (...)
Je vais vous montrer la liste des hooks sur laquelle on a travaillé avec Nicolas Taffin. On a fait une liste des hooks disponibles, à quel moment ils passent et les choses qui sont manipulées. Donc "beforeParsed", on a le "content" et c'est le contenu original du DOM. Par don je me suis trompé, il est pas encore dans le template, il est parsé: Paged.js a analysé le CSS, a analysé l'HTML et a rajouté des classes, des id, un data-set par élément spécifique à Paged.js.
Après on a le chuncker: on a avant que la page soit mise en page, après que la page a été mise en page et après que toutes les pages est été mise en page. Et là dedans, en plus de ces trois grandes étapes, on a un ensemble de sous étapes: avant que le CSS soit parsé, (...) layoutNode, c'est le moment où il va poser un élément dans la page, "render" où il la fabrique pour de vrai, "onOverflow" c'est quand il y a un élément qui sort de la page et "onBreakToken" c'est quand il y a un token qui est créé et qui dit "la découpe a eu lieu dans tel endroit dans le contenu. (...)
Je me suis fait une petite fonction qui créé des blocs à partir du contenu, de type div bien sémantiques et qui va récupérer tout ce qu'il a dans la classe "intro". Il prend le contenu, il créé une div, il lui ajoute une classe "intro" et il prend chacun des éléments qui a cette classe là dans le HTML et auquel il va rajouter les listes numéros et les images qui suivraient l'un de ces éléments. Parce que bien entendu, dans les 3/4 des outils textuels qu'on a, on a pas la possibilité de rajouter des classes aux images ou ce genre de choses. Donc l'idée, c'est vraiment de reconstruire mon DOM. (...)
C'est l'ensemble de mes fonctions mais c'est ce qui est passé avant que Paged.js commence son travail. Ensuite, j'ai un ensemble de scripts qui vont être très spécifiques mais je vais pas tous les regarder parce que c'est pas forcément nécessaire. Le premier script me permet de reconstruire mon DOM et à partir de là je peux construire mes pages en fonction de mes besoins. (...)
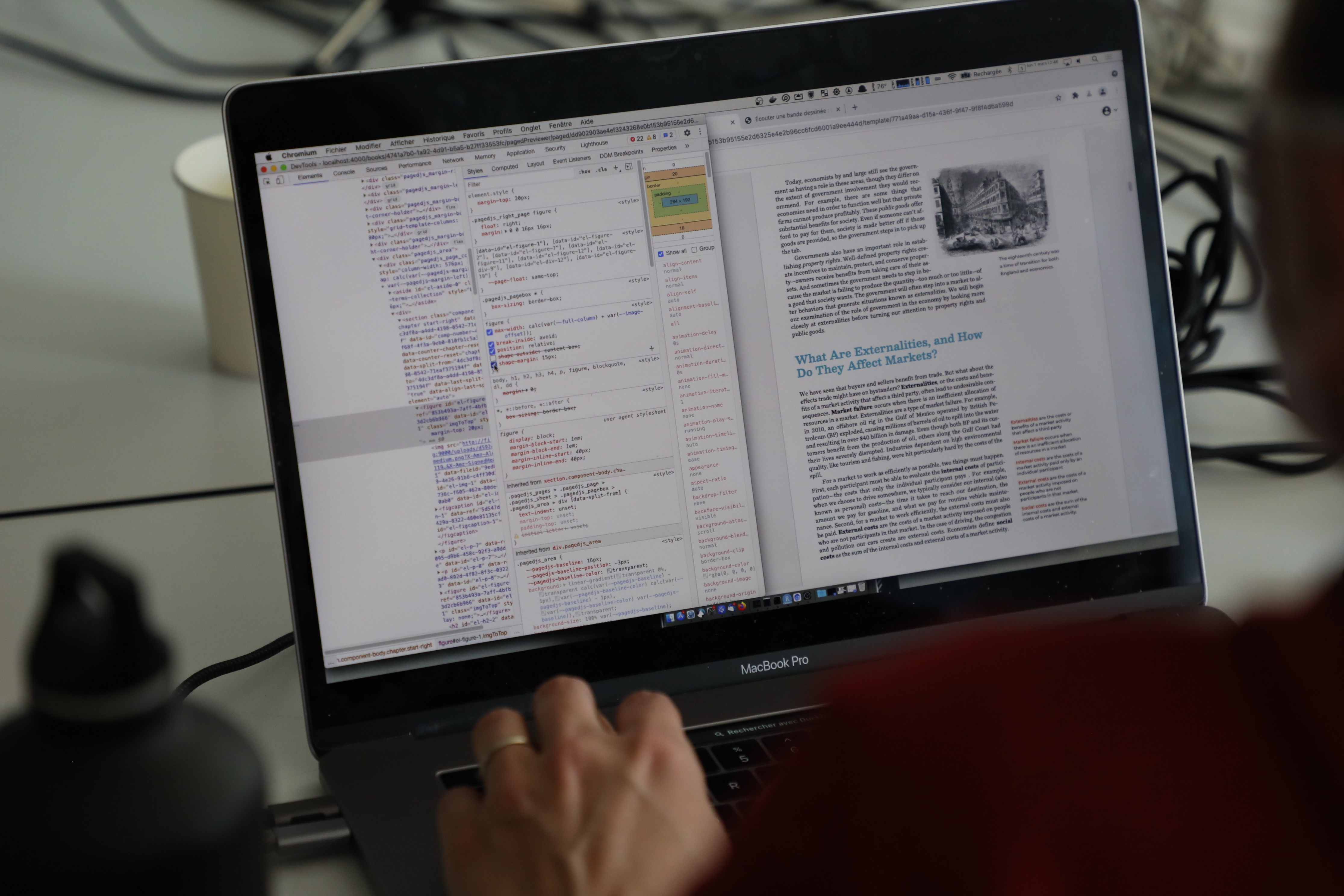
Au moment où il rend l'élément sur la page, il regarde si il a la classe "intro-caption", si c'est le cas il cherche l'image. Si c'est le cas, il sort l'image de ce bloc là et il la met en haut de la page. grosso-modo, il prends l'image et il la met en haut de la page, il sort la caption et il l'a met à la fin de mon texte d'intro. Si vous regardez, on a une intro qui démarre sur la page 3, qui continue sur la page 4 et ici on a un bloc. Ces blocs-là, la façon dont le code est fait, il va commencer par le mettre en haut de page, il va poser le contenu qui du coup va démarrer en dessous. Une fois qu'il a fini la page, il va remonter le contenu parce que je vais prendre mon bloc et le positionner en absolute en bas de page. C'est là où on commence à avoir des choses un peu plus intéressantes qui sont des float top et float bottom.
La façon dont le float top est construit ici [sur une autre pages], c'est une figure qui est positionné en float et qui a ce truc magique qui est le 'shape-outside: content-box'. C'est assez génial parce que c'est un truc qui permet de définir comment se situe l'habillage de texte. [Explication sur l'utilisation du shape-outside pour faire les float bottom]. Cette petite propriété magique qui fait "content-box" permet de dire que c'est seulement le contenu qui est pris en compte. Ce qui veut dire derrière qu'on peut commencer à avoir des float bottom qui tiennent un peu la route
[...]
Le reste de la transcription n'est pas disponible en version publique.